Dostęp do mocy obliczeniowej jest kluczowy dla pełnego wykorzystania potencjału sztucznej inteligencji w biznesie. Nie oznacza to jednak, że do wdrożenia takiego rozwiązania są niezbędne superkomputery.
Partnerem materiału jest deepsense.ai.

W styczniu 2019 roku media obiegła informacja o modelu sztucznej inteligencji AlphaStar, który pokonał czołowych światowych graczy w grze Starcraft II. Wytrenowanie AlphaStar w klasycznych warunkach gry z człowiekiem wymagałoby około 400 lat ciągłej rozgrywki. Jednak dzięki ogromnej mocy obliczeniowej, umożliwiającej błyskawiczne przetwarzanie danych, udało się wyszkolić sieć neuronową w dwa tygodnie.
AlphaStar i podobne modele AI można porównać do szachisty, który osiąga nadludzki poziom dzięki rozegraniu milionów partii. Aby ta nauka nie trwała latami, programiści zapewniają modelowi dostęp do tysięcy szachownic, na których jednocześnie rozgrywa wiele partii. Można to osiągnąć dzięki stworzeniu architektury rozwiązania na superkomputerze, ale można też o wiele prościej: zamawiając wszystkie te szachownice jako instancje (maszyny) w chmurze obliczeniowej.
Zbudowanie wspomnianych modeli wymagało ogromnych nakładów finansowych, do których nie każda firma ma tak swobodny dostęp, jak należący do Google’a twórca modeli AlphaStar i AlphaGo. Nie dziwi więc, że w biznesie nadal pokutuje przeświadczenie, że eksperymenty technologiczne (w tym rozwiązania AI) są drogie i wymagają wyspecjalizowanej infrastruktury.
Potwierdzenie tej tezy znajduje się w opracowaniu AI Adoption Advances, but Foundational Barriers Remain firmy McKinsey. Wynika z niego, że 25% badanych firm wskazuje brak odpowiedniej infrastruktury jako kluczową przeszkodę dla rozwoju sztucznej inteligencji we własnej firmie. Większymi problemami są jedynie brak strategii AI oraz brak ludzi i wsparcia w organizacji – czyli tematy fundamentalne, poprzedzające jakiekolwiek dyskusje infrastrukturalne.
Jak zatem korzystać z dobrodziejstw sztucznej inteligencji oraz uczenia maszynowego (machine learning) bez konieczności uruchamiania wielomilionowych projektów? Są na to trzy sposoby: (1) Precyzyjne określenie zakresu eksperymentów z AI. Konieczny jest dokładny wybór obszarów biznesowych do testowania modeli oraz jasno określone wskaźniki sukcesu. Dzięki okrojeniu badanego przypadku do minimum możliwe jest zbadanie działania rozwiązania bez nadmiernych wymagań sprzętowych; (2) Korzystanie głównie z zasobów chmurowych, które generują koszty, tylko gdy są używane i z racji na efekt skali ich cena jest atrakcyjna; (3) Stworzenie uproszczonego modelu przy użyciu zasobów w chmurze obliczeniowej, co łączy zalety obu poprzednich podejść.
Czasami wystarczy laptop
Z nawet najbardziej skomplikowanym problemem można się zmierzyć, sprowadzając go do formy studium wykonalności, co oznacza maksymalne uproszczenie wszystkich elementów i założeń. Przy ograniczeniu do minimum zbędnych komplikacji i zmiennych do wykonania nieodzownych obliczeń nie potrzeba superkomputerów – najczęściej wystarczy laptop ze średniej półki.
Przykładowe wyzwanie: Firma sprzedająca wiele produktów w różnorodnych kanałach potrzebuje silnika rekomendującego klientom najbardziej interesujące ich artykuły w ramach akcji cross‑sell i up‑sell.
Rozsądnym podejściem do tego problemu jest najpierw określenie konkretnego obszaru biznesowego lub linii biznesowej, której produkty lub ofertę będziemy analizować, a następnie wybór kanału dystrybucji (z perspektywy klienta). Wskazany kanał powinien zapewniać łatwy dostęp do ustrukturyzowanych danych. Idealnym wyborem jest e‑commerce. Dodatkowo można ograniczyć grupę klientów do konkretnego segmentu czy lokalizacji i na takiej bazie rozpocząć budowę oraz testowanie modeli. W ten sposób można uniknąć żmudnego zbierania, porządkowania, standaryzowania i przetwarzania olbrzymiej ilości danych. To właśnie ten etap odpowiada za większość kosztów infrastrukturalnych. Przygotowanie w ten sposób prototypu modelu pozwala sprawnie wejść w fazę testów i weryfikacji działania rozwiązania.
Tak zawężony problem może rozwiązać data scientist wyposażony w dobry laptop. Podobne podejście zastosowała firma Uber, która zamiast tworzyć scentralizowany dział analiz i data science, zatrudniła specjalistę od uczenia maszynowego do każdego zespołu. Dzięki temu we wszystkich działach pojawiają się drobne poprawki automatyzujące i przyspieszające codzienną pracę. Sztuczna inteligencja jest postrzegana nie jako kolejny projekt na poziomie korporacyjnym, a jako użyteczne narzędzie, po które pracownicy sięgają codziennie.
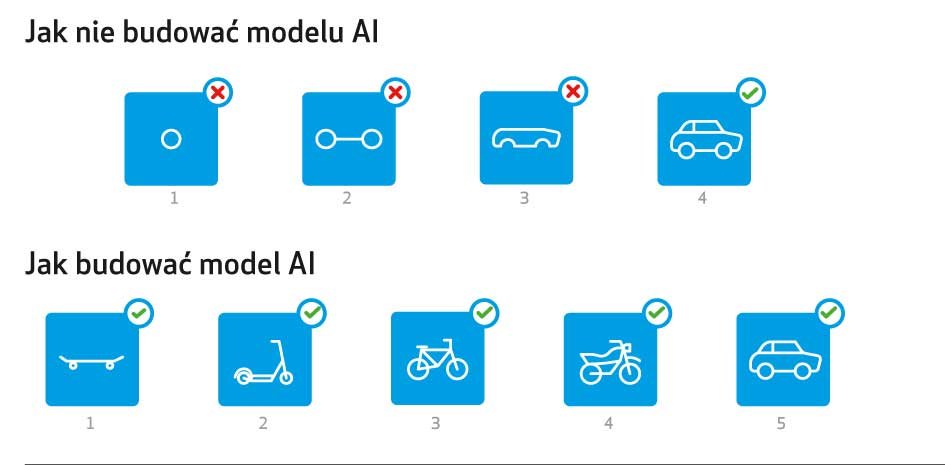
Takie podejście wpisuje się w popularną filozofię iteracyjnego kreowania wartości – której założeniem jest najszybsze zbieranie informacji zwrotnej i włączanie jej w zwinny proces budowy produktu (zobacz grafikę Jak nie budować modelu AI).
Jak skakać, to w chmurę, a nie na głęboką wodę
Ogromna moc obliczeniowa przydaje się przy tworzeniu rozwiązań opartych na sztucznej inteligencji, szczególnie tych bardziej złożonych lub rozbudowanych. Często jest to jednak jedynie etap w rozwoju takiego rozwiązania i może się okazać, że w codziennym jego użyciu dostęp do ogromnej mocy nie jest konieczny.
Oznacza to, że zapotrzebowanie na moc obliczeniową jest skokowe – przez większość czasu nie ma potrzeby uruchamiania najpotężniejszych komputerów. Gdy trenuje się nowy model lub rozwija się możliwości istniejącej sieci neuronowej, konieczny jest dostęp do wielu rdzeni. Im większa moc, tym szybciej sieć zostanie wytrenowana, a model będzie można przetestować, wdrożyć i czerpać z niego korzyści.
Zastosowanie chmury obliczeniowej jest w tym przypadku rozsądnym rozwiązaniem – daje nam elastyczność. Inwestycja we własny sprzęt wiąże się z wieloma długofalowymi kosztami. Zastosowanie chmury pozwala uniknąć takiej sytuacji.
W deepsense.ai regularnie sięgamy po zasoby w chmurze obliczeniowej choćby ze względu na wygodę oraz elastyczność tego rozwiązania. Widzimy to także w pracy z naszymi klientami. Zapotrzebowanie na moc obliczeniową zmienia się w zależności od projektów, ich ilości, natury przetwarzanych danych czy wielkości zbiorów treningowych. Dlatego inwestowanie w stałą infrastrukturę wiązałoby się z dużą trudnością oszacowania potrzebnej mocy. Poprzez zastosowanie chmury obliczeniowej zachowujemy znacznie większą elastyczność.
Czym ta elastyczność jest w praktyce, widać choćby na przykładzie akceleratorów AI, takich jak np. Tensor Processing Unit (TPU) – wyspecjalizowanego procesora zaprojektowanego specjalnie z myślą o uczeniu maszynowym. Jeszcze kilka lat temu wykorzystywanie w uczeniu maszynowym układów opartych na kartach graficznych było nowością. Dziś jest już standardem. Pojawiają się za to nowe technologie, takie jak TPU. Za kilka lat może okazać się, że to właśnie one będą standardem, a przedsiębiorstwa, które zainwestowały w systemy oparte na GPU (karty graficzne), muszą zmodernizować swój park maszynowy. Na pytanie, czy takie wydatki w kolejnych latach będą uzasadnione, każda firma musi odpowiedzieć we własnym zakresie
Robert Bogucki, Chief Technology Officer, deepsense.ai
Kiedy rzeczywiście potrzeba mocy
Większa moc obliczeniowa jest wymagana przy budowie bardziej złożonych rozwiązań, których zadania znacznie wykraczają poza standard i które będą wykorzystywane w znacznie większej skali. Przeszkodą bywa również natura przetwarzanych danych.
Przykładem może być model opracowany przez deepsense.ai na potrzeby National Oceanic and Atmospheric Administration, którego zadaniem było rozpoznawanie na zdjęciach lotniczych poszczególnych waleni biskajskich. Licząca zaledwie 450 osobników populacja jest w tej chwili na krawędzi wymarcia. Tylko śledząc każdego walenia, można chronić te zwierzęta i w odpowiednim czasie udzielić pomocy rannemu zwierzęciu.
Konieczna była chirurgiczna precyzja i uwzględnienie wszystkich dostępnych danych wyciągniętych z nielicznych zdjęć. Opracowane rozwiązanie pozwoliło zautomatyzować proces identyfikacji osobników. Przed wdrożeniem tego rozwiązania biolodzy spędzali z katalogiem zdjęć zwierząt kilka godzin, obecnie sprawdzenie otrzymanych wyników zajmuje im około trzydziestu minut.
Inną, bardzo wymagającą, kategorią jest uczenie poprzez wzmocnienia (reinforcement learning). Model tworzony przy użyciu tej technologii uczy się poprzez interakcje ze środowiskiem oraz zestaw kar i nagród. Tym samym można przeszkolić sieć neuronową do rozwiązywania otwartych problemów oraz działania w zmiennych, nieprzewidywalnych środowiskach na podstawie wcześniej ustalonych zasad, czego najlepszym przykładem jest kontrola samochodu autonomicznego.
W tym przypadku oprócz mocy potrzebnej do trenowania modelu konieczne jest również zapewnienie mu symulowanego środowiska, często nawet bardziej wymagającego niż sama sieć neuronowa. Badacze z deepsense.ai wspólnie z Google Brain pracują nad rozwiązaniem tego problemu poprzez sztuczną wyobraźnię.
Małym nie brakuje odwagi
W przeciwieństwie do poprzednich rewolucji przemysłowych uczenie maszynowe i sztuczna inteligencja mogą być wprowadzane w organizacji metodą drobnych kroków. Zamiast postrzegać uczenie maszynowe jako kolejny gigantyczny projekt w skali całego przedsiębiorstwa, warto przetestować działanie niedużych modeli w optymalizacji wybranych procesów.
Taką filozofię wyznajemy w Google’u. Dzięki temu sztuczna inteligencja jest obecna w każdym naszym produkcie, a użytkownicy sięgają po nią często nawet nieświadomie. Już 12% odpowiedzi wysyłanych przy użyciu poczty Gmail zostało automatycznie wygenerowanych i jedynie zatwierdzonych przez użytkownika. Są to potwierdzenia odbioru, podziękowania lub proste wypowiedzi w rodzaju „tak” lub „nie”. Codzienna praca biurowa składa się z dziesiątek tego typu maili. Każda taka odpowiedź to zaoszczędzony czas.
Wspieranie naszych własnych procesów nie byłoby możliwe, gdyby nie zasoby w chmurze obliczeniowej, po które może w tej chwili sięgnąć każda firma na rynku. Tym samym omija ją konieczność inwestycji w sprzęt oraz budowy własnej, skomplikowanej infrastruktury. Do niedawna była to codzienność wszystkich organizacji chcących rozwijać technologię we własnym zakresie.
Chmura obliczeniowa ma jeszcze jedną, często pomijaną, zaletę – działa na korzyść mniejszych graczy na rynku. Wcześniej dostęp do najnowszych zdobyczy technologicznych umożliwiał efekt skali – jedynie najwięksi gracze mający dostęp do największych środków sięgali po nowości.
Obecnie dostęp do procesora TPU (wyspecjalizowanej jednostki obliczeniowej zaprojektowanej, aby zapewnić najwyższą wydajność przy trenowaniu modeli uczenia maszynowego) może uzyskać nawet analityk danych pracujący na kanapie we własnym domu. Od najnowszych technologii oddzielają nas jedynie wola i odwaga. Małym ich nie brakuje. A co z większymi?
Magdalena Dziewguć, Territory Manager, Google Cloud Platform
Podróż w chmury
W każdym z powyższych przykładów konieczne było zapewnienie dostępu do dużej mocy obliczeniowej. Odpowiedzią na takie skokowe zapotrzebowanie jest chmura obliczeniowa (cloud computing). Do najważniejszych zalet chmury obliczeniowej jako wsparcia w rozwoju modeli uczenia maszynowego należą:
Niskie koszty i brak barier wejścia dzięki modelowi pay‑per‑use. W przypadku chmury obliczeniowej użytkownik płaci jedynie za wykorzystane zasoby. Znacznie spada zatem koszt użytkowania. Szacuje się, że chmura jest nawet 30% tańsza we wdrożeniu i utrzymaniu niż infrastruktura własnościowa. Nie jest potrzebne inwestowanie w sprzęt zdolny do uniesienia skomplikowanych obliczeń, a jedynie opłacenie „sesji treningowej” dla sieci neuronowej. Po wykonaniu obliczeń sieć jest już gotowa do działania. Samo działanie wytrenowanych rozwiązań opartych na uczeniu maszynowym nie jest tak wymagające – sztuczna inteligencja jest obecna np. w aparatach telefonów komórkowych, gdzie poprawia ustawienia techniczne, by zdjęcie wyszło możliwie najlepiej. Z obsługą modeli AI może sobie zatem poradzić nawet procesor w telefonie.
Łatwe możliwości rozwoju i rozbudowy. Przeniesienie zasobów firmowych do chmury daje dostęp do całego wachlarza komplementarnych produktów. Dzięki chmurze obliczeniowej łatwo można udostępnić zasoby zewnętrznym platformom i jeszcze skuteczniej wykorzystać posiadane dane poprzez ich wizualizację i pogłębioną analizę. Raport State of Cloud 2018 firmy RightScale wskazuje, że wraz z dojrzałością organizacji w użytkowaniu chmury rośnie zainteresowanie usługami dodanymi. Wśród przedsiębiorstw określających się jako „początkujące” w wykorzystaniu chmury obliczeniowej jedynie 18% jest nimi zainteresowanych. Wśród „zaawansowanych” odsetek ten sięga 40%. W przypadku wiodących rozwiązań dostępnych jest wiele tych wspierających rozwój uczenia maszynowego – od zwykłego wynajmu procesora i pamięci aż po platformy i gotowe komponenty do automatycznej budowy popularnych rozwiązań.
Stały dostęp do najlepszych rozwiązań. Zaopatrując się w konkretny sprzęt, firma wiąże się z wybranym zestawem technologii. W przypadku rozwoju uczenia maszynowego może to być zakup specjalnych komputerów opartych na procesorach kart graficznych GPU, szczególnie wydajnych przy obliczeniach przeprowadzanych na potrzeby uczenia maszynowego. Jednocześnie cały czas trwają prace nad rozwojem sprzętu, przez co może się okazać, że inwestycja w konkretną infrastrukturę nie była optymalnym wyborem – zamiast GPU lepszym rozwiązaniem może okazać się Tensor Processing Unit, procesor opracowany przez Google’a z myślą o zastosowaniach przy uczeniu maszynowym. Chmura obliczeniowa pozwala więc przy każdej okazji sięgać po najnowsze dostępne technologie – zarówno sprzętowe, jak i oprogramowania.
Ryzyko w przestworzach
Jednym z problemów jest również brak pełnej kontroli nad danymi, która w niektórych branżach lub jurysdykcjach może być wymagana. Nie wszystkie dane można swobodnie wysyłać do ulokowanych poza granicami kraju rozproszonych centrów danych. Z pomocą przychodzą rozwiązania mieszane, czyli korzystanie jednocześnie z chmury oraz własnej infrastruktury i dzielenie danych na te, które muszą pozostać w firmie, oraz takie, które można wysyłać do chmury. W Polsce rozwiązanie tego problemu zapewnić ma powołany niedawno Operator Chmury Krajowej, który zaoferuje usługi cloud computing realizowane w centrach danych na terytorium naszego kraju.
Dopasowane rozwiązania
Obawy związane z brakiem odpowiednich zasobów obliczeniowych do zastosowania uczenia maszynowego są często nieuzasadnione. Wiele modeli można zbudować przy użyciu ogólnodostępnego sprzętu komputerowego (commodity hardware), który już teraz znajduje się w przedsiębiorstwie. A gdy do budowy systemu potrzebne jest długotrwałe trenowanie danego modelu przy użyciu ogromnych ilości danych, potrzebną moc i infrastrukturę można w prosty sposób pozyskać z chmury obliczeniowej.
Uczenie maszynowe jest w tej chwili jednym z najgorętszych trendów biznesowych, łatwy dostęp do chmury oznacza w praktyce demokratyzację mocy obliczeniowej – po gigantyczne zasoby równie szybko może sięgnąć zarówno niewielka firma, jak i najsilniejszy gracz na rynku. Między chmurą obliczeniową a uczeniem maszynowym występuje sprzężenie zwrotne, którego nie da się zignorować.
PRZECZYTAJ TAKŻE: Tu wpisz tekst »
Dlaczego działy biznesowe potrzebują chmury bardziej niż dział IT?
Chmury obliczeniowe, IT Przemysław Galiński PLArtykułów o chmurze obliczeniowej napisano już wiele. Ten będzie trochę inny.


